

Формы в системе PolyAnalyst: генерация шаблонных документов Одним из вариантов...
Read MoreОсвоение языковых моделей: подробный разбор входных параметров
23 января 2024
Если вам когда-либо приходилось использовать языковую модель в интерактивной среде или через API, то скорее всего ваша работа начиналась с выбора нескольких входных параметров. Однако, у многих из нас возникают вопросы по поводу назначения и правильного использования этих параметров.
Эта статья поможет вам научиться использовать параметры для решения проблемы выдачи неверной информации (галлюцинаций) и однообразия в результатах работы языковых моделей. Мы также рассмотрим другие тонкие настройки, оптимизирующие поведение моделей. Как и в случае с промпт-инжинирингом, правильная настройка параметров поможет вам добиться от модели 110% эффективности.
В данной статье подробно рассматриваются пять основных входных параметров: температура (temperature), параметры семплинга top-p и top-k, штрафы за частоту и присутствие (frequency penalty и presence penalty). Вы узнаете, как эти параметры помогают достичь баланса между качеством и разнообразием результатов работы модели.
Устраивайтесь поудобнее, мы начинаем!
Содержание
Вводная информация
Для начала важно ознакомиться с общими принципами работы языковых моделей. Начнём наше погружение с самых основ.
При анализе документа языковая модель преобразует его в последовательность токенов. Токен — небольшой, понятный для модели фрагмент текста: слово, слог или отдельный символ. Например, предложение «Мегапьютер лучше всех!» может быть разбито на пять токенов: [«Мега», «пьютер «, «лучше «, «всех», «!»]. Этот процесс осуществляется с помощью токенайзера.
Большинство известных нам языковых моделей работают по принципу последовательной генерации цепочки токенов: модель предсказывает каждый следующий токен, основываясь на ранее сгенерированной последовательности. Этот подход называется авторегрессионной генерацией.
Именно поэтому ChatGPT выводит слова на экран по одному: слова появляются по мере генерации.
Чтобы сгенерировать токен, языковая модель присваивает каждому токену в своём словаре оценку правдоподобия, т.е. вероятности его появления в тексте. Модель оценивает, насколько подходящим является токен для продолжения заданного текста. При хорошем соответствии токен получает высокую оценку правдоподобия, при слабом соответствии — низкую. Сумма оценок правдоподобия для всех токенов в словаре модели всегда равна единице.
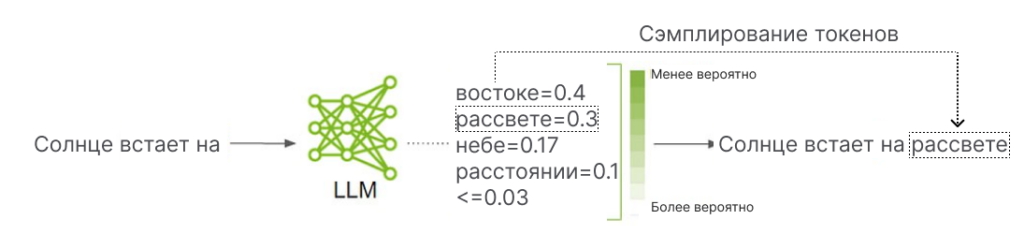
После присвоения токенам оценки правдоподобия, модель инициирует схему семплирования токенов для выбора следующего элемента последовательности. В этом методе может быть задействован элемент случайности, чтобы языковая модель не давала один и тот же ответ на одинаковые вопросы каждый раз. Такой подход с использованием элемента случайности может быть полезным в работе чат-ботов и в ряде других случаев.
Если кратко: Языковые модели разбивают текст на фрагменты, прогнозируют следующий фрагмент в последовательности, добавляя при этом элемент случайности. Для получения определенного результата эти действия повторяются необходимое количество раз.
Качество, разнообразие и температура
А зачем вообще нам выбирать второй по оценке токен, третий или любой другой, если мы уже нашли самый подходящий? Разве мы не хотим видеть наилучшее продолжение (имеющее наивысшую оценку правдоподобия) при каждом ответе? Часто ответ будет утвердительным. Однако, если всегда выбирать наилучший токен, то каждый раз ответы будут одинаковыми. Для достижения разнообразия в ответах иногда приходится идти на компромисс с точки зрения их качества. Этот компромисс известен как дилемма качества и разнообразия.
Решить эту дилемму машине помогает температура. Низкая температура означает более высокое качество, а высокая температура – увеличение разнообразия. При «нулевой» температуре модель всегда выбирает токен с максимальной оценкой правдоподобия, что приводит к полному отсутствию разнообразия в результатах, но гарантирует, что мы всегда получаем самое качественное продолжение по оценке модели.
В большинстве случаев нулевая температура является предпочтительной при решении задач в текстовой аналитике. Это происходит потому, что чаще всего при анализе текста имеется единственный “правильный” ответ, который мы стремимся получить при каждом запросе. При нулевой температуре у нас есть все шансы получить этот ответ с первого раза. Мы предпочитаем устанавливать температуру на ноль при извлечении сущностей, извлечении фактов, анализе тональности и для многих других задач, которые мы решаем как аналитики. Как правило, если промпт предоставляется модели однократно, всегда следует устанавливать температуру на ноль, т.к. это повышает вероятность получить хороший результат.
При выборе более высоких значений температуры модель демонстрирует большую креативность и разнообразие ответов. Однако это также может привести к увеличению количества мусорных результатов и галлюцинаций, что в среднем снижает качество ответов. Температура выше нуля применяется, когда мы хотим дать один и тот же промпт модели несколько раз и получить множество креативных ответов. Таким образом, если ваша цель — задать один и тот же вопрос дважды и получить разные ответы, рекомендуется использовать только ненулевые значения температуры.
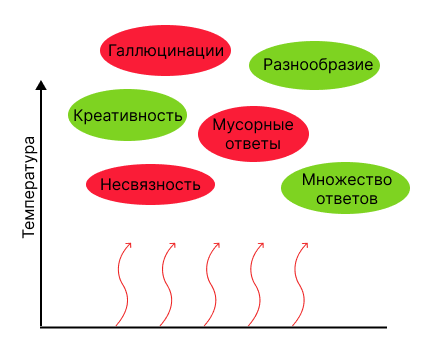
Дилемма качества и разнообразия
При повышении температуры увеличивается не только разнообразие, креативность и
многообразие ответов, но и количество несвязных, мусорных ответов и галлюцинаций.
А зачем вообще получать два разных ответа на один и тот же вопрос? В ряде случаев это может оказаться полезным. Например, существует метод, при котором генерируется несколько ответов на один промпт, а затем из них выбирается самый лучший. Этот подход часто приводит к более качественным результатам, чем если бы мы задали вопрос один раз при нулевой температуре. Еще один практический пример — это генерация синтетических данных, где необходимо создать не одну, а несколько синтетических точек данных. Такие и другие сценарии могут быть подробно описаны в последующих статьях. Однако во многих ситуациях требуется получить всего один ответ. Если сомневаетесь, используйте нулевую температуру!
Важно и следующее: хотя в теории при нулевой температуре модель выдает один и тот же ответ при каждом повторении вопроса, на практике все может быть иначе! Это объясняется тем, что процессоры, на которых запущена модель, могут допускать небольшие погрешности вычислений, например погрешности округления. Такие погрешности вносят в расчеты небольшую случайность даже при нулевой температуре. Изменение всего одного токена из-за погрешности может привести к целому каскаду изменений далее по тексту, и на выходе мы получим совершенно другой результат. Но будьте уверены, что такие события лишь незначительно влияют на качество, и мы упоминаем это только для того, чтобы определенная случайность при нулевой температуре не стала для вас сюрпризом.
Помимо температуры существует много способов решения дилеммы качества и разнообразия. В следующем разделе мы рассмотрим определенные варианты использования техники семплирования при ненулевой температуре. Вы можете пропустить этот раздел, если вам достаточно использования нулевой температуры, поскольку выбор следующих параметров при нулевой температуре никак не повлияет на ответы.
Если кратко: Увеличение температуры способствует разнообразию, но снижает качество из-за случайности в ответах модели.
Семплирование с помощью параметров top-k и top-p
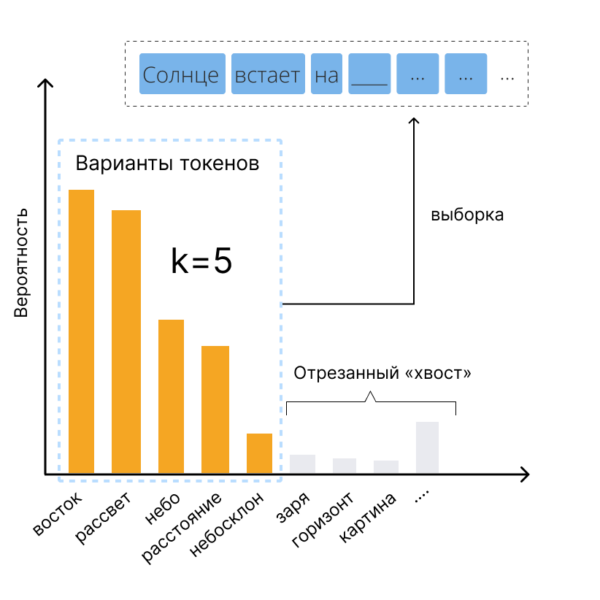
Одним из распространенных способов настройки выбора токенов является top-k сэмплирование. Этот метод во многом похож на стандартное семплирование с использованием температуры, но есть важное отличие: самые маловероятные токены исключаются заранее, и дальнейшая работа ведется только с определенным числом (k) наиболее вероятных токенов. Преимуществом этого метода является исключение наименее удачных токенов из процесса выбора..
Предположим, мы хотим найти продолжение для фразы «Солнце встает на…». Без использования top-k семплирования модель будет рассматривать любой токен из своего словаря как потенциальное продолжение фразы. Значит, существует определенная, хоть и небольшая, вероятность того, что на выходе мы получим что-то вроде «Солнце встает на кухне». С применением же top-k семплирования модель отфильтровывает наименее подходящие токены и концентрируется только на выбранном количестве наиболее вероятных вариантов. Отсекая этот «хвост» некорректных токенов, мы уменьшаем разнообразие ответов, но значительно повышаем их качество.
Дилемма качества и разнообразия
При повышении температуры увеличивается не только разнообразие, креативность и
многообразие ответов, но и количество несвязных, мусорных ответов и галлюцинаций.
Top-k семплирование – это способ совместить несовместимое, ведь, в отличие от использования только температуры, этот метод позволяет сохранять необходимый уровень разнообразия без существенной потери качества. Ввиду своей универсальности и высокой эффективности, техника top-k семплирования породила множество вариаций.
Одной из популярных вариаций top-k семплирования является top-p семплирование, также известное как ядерное семплирование. Top-p семплирование очень похоже на top-k, но для определения границы отсечения токенов в нем вместо отсечения по порядку в рейтинге правдоподобия используется отсечение по непосредственным значениям оценки правдоподобия. Если говорить конкретнее, в top-p семплировании учитываются только те токены с самыми высокими оценками, суммарная вероятность которых превышает заданный порог p, в то время как остальные токены отбрасываются.
Top-p семплирование имеет очевидное преимущество перед top-k семплированием в случаях, когда среди токенов, претендующих на следующую позицию в тексте, присутствует множество посредственных или плохих вариантов. Предположим, существует лишь небольшое количество подходящих по смыслу токенов и десятки менее осмысленных вариантов. Если бы мы использовали top-k, где k=25, в это количество попало бы множество маловероятных токенов. И наоборот, при top-p семплировании с отсечением нижних 10% распределения вероятностей, мы бы рассматривали только хорошие токены, отбросив остальные.
На практике семплирование с использованием top-p обычно дает более качественные результаты, чем top-k. Так как эта методика работает с кумулятивной вероятностью, она адаптируется к исходному контексту, предоставляя более гибкий подход к отсечению мусорных результатов. В целом, и top-p, и top-k можно использовать в сочетании с ненулевой температурой для достижения большего разнообразия ответов модели без особой потери качества, однако top-p семплирование обычно справляется с этой задачей лучше.
Совет: для обоих параметров – top-p и top-k – более низкое значение означает более строгую фильтрацию. При нулевых значениях этих параметров будут отсекаться все токены, кроме самого высокорангового, т.е. достигается тот же эффект, что и при использовании нулевой температуры. Поэтому, используя эти параметры, учитывайте, что слишком низкие их значения полностью устранят разнообразие в ответах.
Если кратко: При использовании параметров top-k и top-p мы получаем повышение качества с небольшим снижением разнообразия. Это достигается путем отсечения наихудших токенов перед случайным семплированием.
Штрафы за частоту и присутствие
Перед тем как подвести итоги, давайте обсудим еще два параметра: штраф за частоту (frequency penalty) и штраф за присутствие (presence penalty). Использование этих параметров представляет собой ещё один способ решения дилеммы качества и разнообразия. В отличие от параметра температуры, при применении которого разнообразие достигается путём добавления элемента случайности в процедуру семплирования токенов, штрафы за частоту и присутствие увеличивают разнообразие, препятствуя выбору токенов, уже появлявшихся в тексте. Это уменьшает использование частотных токенов и стимулирует модель к генерации более оригинальных вариантов.
Модель получает штраф за частоту (frequency penalty) за каждое повторение одного и того же токена в тексте. Это снижает вероятность частого использования одних и тех же токенов/слов/фраз и, как следствие, заставляет модель рассматривать более широкий спектр тем и чаще их менять. В свою очередь штраф за присутствие (presence penalty) является фиксированным и применяется единожды, если токен уже появлялся в тексте. Это стимулирует модель использовать новые токены/слова/фразы и способствует рассмотрению более широкого спектра тем и более частой их смене, при этом не принуждая модель полностью отказываться от повторного употребления часто используемых слов.
Так же, как и температура, штрафы за частоту и присутствие уводят нас от «лучшего» ответа к более креативному. Однако это достигается не путём добавления элемента случайности, а через целевые «штрафы», которые с особой точностью рассчитываются для добавления разнообразия в ответ. В тех редких случаях, когда требуется ненулевая температура (например, когда нужно множество ответов на один запрос), вы также можете рассмотреть возможность добавления небольших штрафов за частоту и присутствие, чтобы добавить креативности в результат. Но для промптов, подразумевающих только один верный ответ, который вы хотите получить с первой попытки, наивысшая вероятность успеха достигается тогда, когда все эти параметры установлены на ноль.
Как правило, если существует только один правильный ответ и вы задаете свой вопрос один раз, рекомендуется устанавливать штрафы за частоту и присутствие на ноль. Но что делать, если правильных ответов может быть множество, как, например, в задаче по реферированию текста? В этом случае возможны варианты. Если вы считаете, что результат работы модели скучный, банальный, содержит повторы или не передает идею полностью, то разумное применение штрафов за частоту или присутствие может оживить картину. Однако наша итоговая рекомендация по этим параметрам та же, что и для температуры: если сомневаетесь, установите параметр на ноль!
Отметим, что несмотря на то, что и температура, и штрафы за частоту/присутствие добавляют разнообразие в ответы модели, это разнообразие отличается по типу. Штрафы за частоту/присутствие увеличивают разнообразие в пределах одного ответа, т.е. ответ будет включать больше уникальных слов, фраз, тем и идей. Но если вы подаете один и тот же промпт дважды, то вы вряд ли получите два разных ответа. В отличие от упомянутых параметров, температура увеличивает разнообразие между ответами. Это значит, что если вы даёте модели один и тот же промпт несколько раз при более высокой температуре, вы получаете более широкий набор вариантов ответа.
Чтобы разграничить эти типы разнообразия, назовем их «разнообразие в пределах ответа» и «разнообразие между ответами». Параметр температуры способствует увеличению как разнообразия в пределах ответа, так и разнообразия между ответами, в то время как штрафы за частоту/присутствие повышают только разнообразие в пределах ответа. Следовательно, когда нам нужно разнообразие, выбор параметров зависит от типа разнообразия, которого мы хотим добиться.
Если кратко: Штрафы за частоту и присутствие расширяют спектр рассматриваемых моделью тем и заставляют чаще их менять. Штраф за частоту также увеличивает разнообразие в выборе слов, снижая повторяемость слов и фраз.
Памятка по настройке параметров
Данный раздел представляет собой практическое руководство по настройке входных параметров модели. Сначала рассмотрим строгие правила, которые помогут определить, какие параметры следует установить на ноль. Затем мы дадим несколько советов, которые помогут вам настроить параметры с ненулевыми значениями.
Настоятельно советуем вам воспользоваться этими рекомендациями при настройке параметров. Добавьте эту страницу в закладки прямо сейчас, чтобы не потерять!
Правила установки параметров на ноль:
Температура:
- Для получения одного ответа на промпт: ноль.
- Для получения нескольких ответов на промпт: ненулевое значение.
Штрафы за частоту и присутствие:
- При наличии одного правильного ответа: ноль.
- При наличии нескольких правильных ответов: по вашему выбору.
Top-p/Top-k:
- При нулевой температуре: не влияет на результат.
- При ненулевой температуре: ненулевое значение.
Если у используемой языковой модели имеются дополнительные параметры, не указанные выше, оставьте их значения по умолчанию.
Подсказки по установке ненулевых значений параметров:
Составьте список параметров, которые должны иметь ненулевые значения, а затем протестируйте несколько сценариев, чтобы посмотреть, какой из них работает лучше. Если согласно вышеуказанным правилам определенный параметр должен быть установлен на ноль, то и оставьте его значение равным нулю!
Настройка температуры/top-p/top-k:
- Для увеличения разнообразия/случайности повысьте температуру.
- При работе с ненулевыми температурами начните со значения top-p ~ 0.95 (или top-k ~ 250), а затем снижайте его при необходимости.
Возможные проблемы и их решение:
- При слишком большом объеме бессмысленных, мусорных ответов или галлюцинаций снизьте температуру и/или top-p/top-k.
- Если температура высокая, а разнообразие низкое, увеличьте значение параметра top-p/top-k.
Совет: в некоторых интерфейсах можно использовать параметры top-p и top-k одновременно, но мы предпочитаем более простой вариант, при котором выбирается или первый, или второй параметр. Параметр top-k более прост для использования, но top-p часто более эффективен.
Настройка штрафа за частоту и штрафа за присутствие:
- Для получения более разнообразных тем и концепций увеличьте значение штрафа за присутствие.
- Для большего разнообразия и меньшей повторяемости в языке ответов увеличьте значение штрафа за частоту.
Возможные проблемы и их решение:
- Если ответы кажутся вам несвязными, а темы меняются слишком быстро, уменьшите значение штрафа за присутствие.
- Если количество новых и необычных слов в ответах слишком велико, либо если штраф за присутствие установлен на ноль, но темы все равно меняются слишком часто, уменьшите значение штрафа за частоту.
Если кратко: Используйте данный раздел как памятку для настройки языковых моделей. Скорее всего вы забудете все эти правила, поэтому добавьте эту страницу в закладки и используйте как памятку при необходимости.
Заключение
Способов выбора токенов существует огромное множество. Среди других известных стратегий стоит выделить поиск по лучу (beam search) и адаптивную выборку (adaptive sampling). Однако, чаще всего используются те параметры, о которых мы говорили в нашей статье: температура, top-k, top-p, штраф за частоту и штраф за присутствие. Это параметры, которые вы найдете в таких моделях, как Claude, Llama и GPT. В данной статье мы показали, что все эти параметры можно использовать для поиска баланса между качеством и разнообразием.
В заключение стоит упомянуть еще один входной параметр: максимальная длина токена. Максимальная длина токена – это то предельное значение, достигнув которого модель перестает выводить свой ответ, даже если этот ответ не завершен. После сложных описаний выше такое определение, скорее всего, не потребует дальнейших пояснений.🙂
По мере продолжения данной серии статей мы будем глубже погружаться в сложные темы. В следующих статьях мы обсудим промпт-инжиниринг, выбор правильной языковой модели для вашего сценария и многое другое! Оставайтесь с нами и продолжайте открывать огромный мир языковых моделей с «Мегапьютер Интеллидженс».
Если кратко: При любых сомнениях устанавливайте температуру и штрафы за частоту и присутствие на ноль. Если это не работает, обратитесь к памятке выше.
ДРУГИЕ НОВОСТИ И СТАТЬИ

Вебинар: «Формы ввода в системе PolyAnalyst: оптимизация сбора данных»
Формы ввода в системе PolyAnalyst: оптимизация сбора данных Данные для...
Read More